【NLP】Day 13: 可不可以再深一點點就好?深度學習基礎知識:你需要知道的這些那些
人類與動物的學習大都是非監督學習。所以說如果「智慧」是一塊蛋糕,那麼非監督學習才是蛋糕本體,監督學習則是那層糖霜,強化學習不過是上頭的櫻桃。
Most of human and animal learning is unsupervised learning. If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.
楊立昆 Yann LeCun
不知道昨天大家有沒有看到一則偏宅的新聞,就是星際大戰中達斯維達的配音員詹姆士・厄爾・瓊斯(James Earl Jones),從今開始正式不再為達斯維達配音。我們再也沒有機會聽到本人講那經典的台詞:

喔,對了,防雷警報,達斯維達其實是路克・天行者的老爸。(誰在乎?)
但是新聞還說,雖然本人不再配音,我們在電影中仍然還是可以聽得到他那經典的呼氣聲,並感受它強大的原力?為什麼?這一切都拜那個離我們又遙遠又接近的深度學習技術所賜。
其實不僅僅是語音合成,文本處理上現在也很流行利用深度學習的技術來完成任務。今天,就讓我們先來簡單大概了解什麼是深度學習,還有大家在吵什麼。
釐清名詞觀念
在開始之前,我們得要先釐清名詞觀念。從以前到現在,我們已經學到了好多名詞:人工智慧、機器學習、深度學習、監督式學習、非監督式學習,那這些名詞之間到底有什麼不一樣呢?我們可以這樣理解:
![]()
Source: NVIDIA
人工智慧是一個「雨傘術語」(umbrella term),而機器學習則是人工智慧底下最廣為人知的一個分支。主要目的在於設計和分析一些讓電腦可以自動「學習」的演算法,並利用規律對未知資料進行預測。機器學習又是另外一個「雨傘術語」,因為機器學習又根據演算法分為很多種不同的學習方法,我們這邊提到了監督式學習跟非監督式學習,如果沒看過我之前針對兩者差別進行的介紹,可以去看這篇 **Day 10: 進入偉大航道!機器學習基礎知識:你需要知道的這些那些**。而深度學習是機器學習的其中一種方式。
什麼是深度學習?
深度學習作為機器學習的其中一個分支,若要「沒那麼精確」但要淺顯易懂的解釋,你可以將深度學習理解成「比較深的神經網路」目的在於將資料放進多個節點,經過線性以及非線性的轉換,從原始資料中自動抽取足以代表資料的特徵,自動抽取特徵這點又被稱為表徵學習(representation learning),最終都可以得到非常優秀的結果。
類神經網路通常會有好幾層,每一層會有許多個節點(perceptron),就像人類的神經系統中,神經元與神經元之間的連結一樣,節點與節點之間也會彼此傳遞資訊,之後再經過激勵函數(activation function)轉換成輸出。
為什麼深度學習逐漸變成主流?
但其實深度學習的歷史已經非常悠久了。早在六七零年代,就有電腦科學家嘗試重現生物神經網路的架構,希望電腦可以達到跟人類一樣的優秀學習能力。但礙於當時電腦的運算能力還跟不上理論,再加上數位化的資料並不多,無法提供神經網路好的學習資源,所以當時神經網路仍無法展露頭角。
但現在拜於網路與資訊技術的進步,有越來越多的數位資料可以提供這些神經網路小試身手,除此之外,逐漸成熟的GPU演算技術也幫助了神經網路的運算,速度也有大幅成長(但仍然很慢),天時地利人和之下,神經網路這個名詞才漸漸重新浮出檯面。
跟前面提到的機器學習有什麼不一樣?

一般來說,像是我們先前所說的貝氏分類以及羅吉斯回歸這樣的監督式機器學習,都會需要我們手動加入特徵,而這些特徵都是透過我們人類觀察而得的;人工神經網路乃至於深度學習,其實並不需要我們人類進行特徵工程,深度學習模型會自己學習特徵並自動分類,最後輸出分類,但模型找的特徵可能跟我們一般所認知的特徵會有點差距就是了,也就是說,我們會看不懂神經網路找到的特徵。因此,人工神經網路也是黑盒子模型的一種,這部分後面我們會再提。
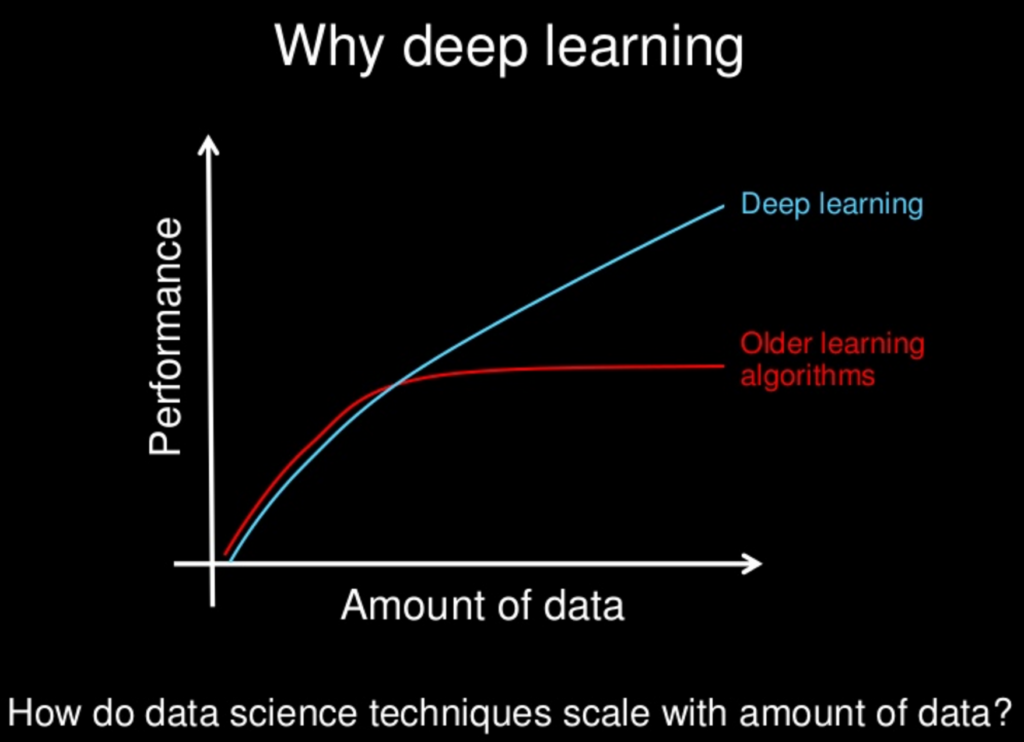
也就是說,資料越多,神經網路所能夠學的特徵就越多,深度學習模型的表現也就越好,好過過去監督式的機器學習模型。
可不可以再深一點點就好?越深越好?
深度學習的一個很常被討論的問題就是,既然叫深度學習,是不是越深就越好?現代知名電腦科學家楊立昆(Yann LeCun)在2008年的論文 Scaling Learning Algorithms towards AI 中就提到,在特定資料量底下,淺層架構的神經網路運算上或許沒辦法達到它最好的表現,深層才能達到最大效益。台大李宏毅老師在機器學習課程中也有提到,神經網路好像疊越多層、神經元越多,表現就越好。那我們就這樣一直無腦疊下去就好了嗎?模型就會越好嗎?
深度的特性反而是一把雙面刃?
後面我們會提到加深神經網路在優化上可能會發生的問題,比如像是神經網路的運算時間計算量大、耗時,即使是一個兩層三節點的神經網路,時間消耗仍然為NP-Complete,NP-Complete就是運行複雜程度的等級,詳細可以來看這篇前輩的文章。另外,也因為梯度消失以及梯度爆炸的現象(後面文章會介紹),也會導致神經網路找不到最佳解,你可以回想前面我們說羅吉斯迴歸為凸函數,找得到最小值;但神經網路為非凸函數,有可能只找到局部最小值,那該怎麼辦呢?
答案是,不怎麼辦!因為我們不能保證模型找到最佳解,但是找到的最小值已經非常逼近最佳解,也就是說已經夠好到足以幫助人類完成許多任務了!
所以其實還是老話一句,越深越好?還是要看任務是什麼,找到最適合的方法才是最重要的。