【NLP】Day 16: 跟你我一樣選擇性記憶的神經網路?深度學習:長短期記憶 LSTM
記憶是個很奇妙的東西。他並不如我想像中那樣運作的。我們太受限於時間了,尤其是時間的順序…
《異星入境》Louise Banks
昨天我們剛介紹完循環神經網路(Recurrent Neural Network),提到說雖然循環神經網路很常被拿來利用在自然語言處理上,原因是因為循環神經網路有記憶的功能,可以考慮到輸入文本的上下文關係,並藉此來達到更好的效果。
但再厲害的技術,也都會有它優缺點,就如同我第一週所說的那樣,科學的演進都源自於對完美的追求,這也正是 Steven Pinker 在《再啟蒙的年代》一書中所說,只要是可以衡量的事物,而這些事物若是有所變化的,那就是人類社會便是一直在進步的路上邁進。
所以說同樣地,RNN 也有先天上的缺陷。像是因為過多層神經網路導致的梯度爆炸或是梯度消失,影響了模型學習成果以及表現,最後的準確度反倒下降了。昨天說到,LSTM 就是 RNN 的是日救星。
長短期記憶模型(Long Short-term memory)
這邊用一個簡單的例子再來重新解釋梯度爆炸跟梯度消失:假如說我們今天利用以下的資料訓練一個可以完成QA任務的循環神經網路。
1 | 魯夫說他想成為海賊王 |
在最後測試模型時,問了模型:「是誰想要成為海賊王?」。這時候可能會出現一個問題:
記不記得我們先前所說 RNN 的記憶特性,而會有這個特性正是因為模型也會將先前所學習的詞彙資訊(權重)在隱藏層中傳遞,最後才會得到的結果。之後,模型會將這個結果進行反向傳播,也就是模型在「反省」先前的學習成果時,都會乘上一個自己的參數 ,若這個參數
的話,在資訊通過不同節點的過程中,若太多層神經網路,則會越乘越小,最後無限逼近於0,模型也就「忘記」先前所學的資訊,是為梯度消失;反之,若
,某個資訊的概率也就越乘越大,而神經網路就被撐死了,是為梯度爆炸。

由於「是誰想要成為海賊王?」的答案(魯夫)在訓練資料中幾乎是在最前面的位置。若模型產生梯度消失的現象,答案在訓練的過程中就會漸漸地被模型「忘記」,最後模型就無法正確回答問題的答案,準確率就下降了。而長短期記憶就可以有效解決這個問題。
到底什麼是LSTM?
LSTM(Long Short-term memory),作為循環神經網路的一個變體,可以先從這張圖來理解,在這邊允許我借用左岸朋友莫煩大大的劇情比喻。

我們可以這麼理解,首先將藍色粗線視為電影的主線劇情、紅色線是為支線劇情,而輸入、忘記、以及輸出都是劇情的「把關者」。今天,「輸入把關者」在看電影時,會決定支線的劇情有多少對電影結局有影響,並依照劇情重要程度寫入主線劇情;但假如這些分線劇情會改變我們對於先前主線劇情的看法的話,「忘記把關者」就會將之前的主線劇情忘記,按照比例替換成現在的新劇情。也就是說,主線劇情的組成主要取決於「輸入把關者」跟「忘記把關者」。也就是說,相對於什麼都記,但時間一久就會忘記的單純循環神經網路,LSTM 則是會「選擇重點記,而且記得比較久」。
熟悉概念後,我們來看看數學原理以及模型吧!
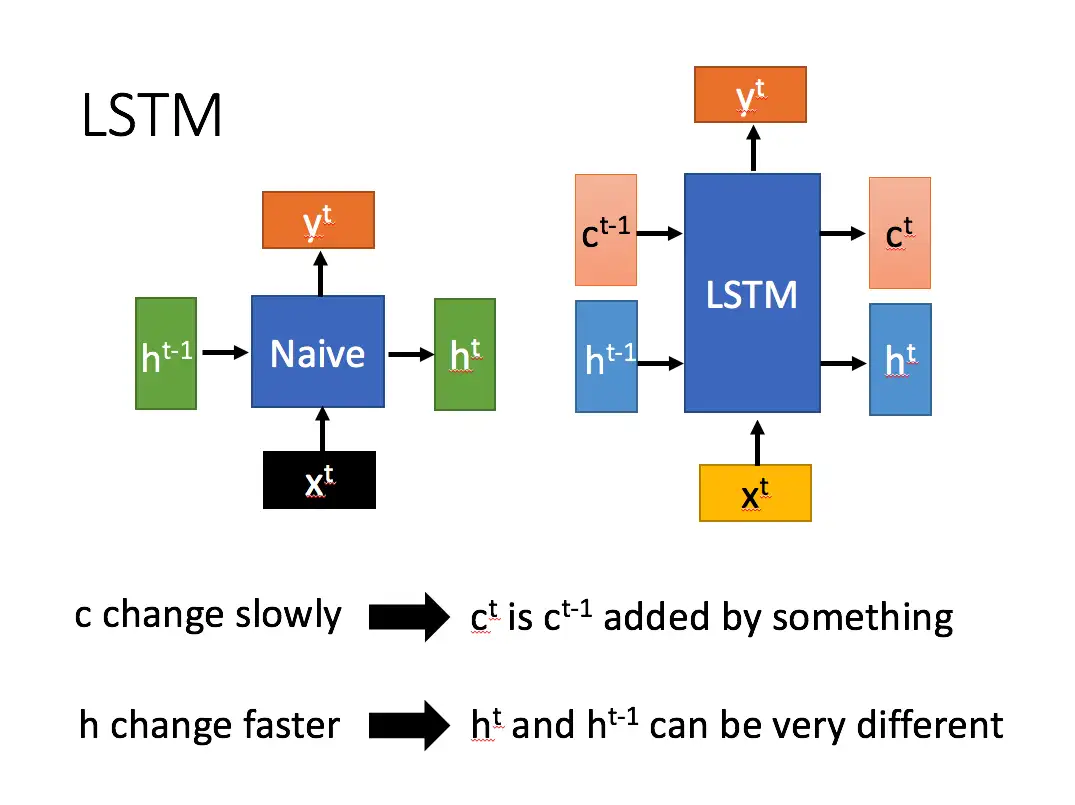
這是台大李弘毅教授機器學習課程中的投影片。在圖中,我們可以看到左邊的是一般的循環神經網路,右邊的則是 LSTM。可以發現,兩者最大的差別就是,LSTM 多了一個變數 ,稱為cell state,也就是前面所說的支線劇情。
改變速度很慢且幅度小,而
的改變速度則較快,而且幅度比較大。
在進入一個新節點時,總共得到四個狀態,分別是,
,
,
。
作為主要的資料輸入,而另外由激勵函數所包起來的
,
,
,則是作為前面所說把關的三個「門閥」。

而這四個狀態分別在長短期記憶的一個節點中,分別在運算的三個階段中扮演著不一樣的角色。先讓我們來看看以下這張圖,其中⊙代表矩陣相乘,⊕代表矩陣相加。(高中數學,還記得吧!):

在這張圖中的運算過程共分成三個階段:
- 忘記階段
在這個階段會選擇性忘記上一個節點所傳來的資訊,簡單來說,就是決定「把重要的記起來,把不重要的忘記」。實際上的運算是,作為遺忘閥(forget gate),像篩子一樣,來控制上一個階段的
哪些需要記得,哪些需要忘記。
- 選擇記憶階段
而在這個階段,LSTM 則會決定哪些是重要的資訊,而哪些不是,並將重點記起來。主要是透過輸入閥(input gate)來決定當前的輸入內容
哪些是重點,哪些不是。
以上兩者所得結果相加,就會是這個階段的
。
- 輸出階段
這個階段則是以前述兩者之和的縮放後,以
來決定經過
。
問題與討論
在過去讀書階段中,各位一定都有碰過兩種同學,一種是死命地想辦法將所有資訊記下來的同學,另一種則是只記重點,一些太枝微末節的小細節就會選擇性地放棄。而因為前者想要將所有東西都記下來,看起來好像很厲害,但時間一久反而會忘記最重要的重點,考試的表現就容易比較差,這種的大家通常都會說「沒有讀書方法」;反而是後者因為只記重點,所以記的東西就比較少,反而不容易忘記,考試的表現就會比前者還要好。
所以說,拉回來神經網路,比起 RNN 那樣死命地將所有的資訊記起來,不僅容易忘記先前所記下來的資訊,最後的表現也不會好;相對的 LSTM 會忘記不重要的資訊,只記得重要的,表現結果就會比較好。
需要改進的地方
- 語意限制:同樣是RNN的一種,所以也遺傳了RNN的其中一個缺點,詳見:Day 15: 圓圓圈圈圓圓~深度學習:循環神經網路 RNN
- 訓練複雜度提升
相對於 RNN,我們光是看圖就可以發現,LSTM 其中新增了許多的參數,那一旦資料量提升,訓練複雜度也就會增加。而為了解決這個問題,資訊科學家又發明了與LSTM相同效果,訓練又較不複雜的 GRU(Gate Recurrent Unit),來搭建資料量大的模型,也就是我們明天的文章內容。
下一篇文章
若你有空,也歡迎來看看其他文章
➡️ 【NLP】Day 15: 圓圓圈圈圓圓~深度學習:循環神經網路 RNN
➡️ 【NLP】Day 14: 神經網路也會神機錯亂?不,只會精神錯亂…深度學習:前饋神經網路
➡️ 【NLP】Day 13: 可不可以再深一點點就好?深度學習基礎知識:你需要知道的這些那些