【NLP】Day 18: 沒有什麼是一條神經網路解決不了的,如果有,就兩條!深度學習:BiLSTM
我們透過最具革新性且客製化的裝修結構,將兩片晶片合在一起。這種雙晶片的結構領先於現今業界的任何一種晶片。
Apple Event, March 8, 2022, Introduction to Apple M1 Ultra
不知道你是否記得,我們在圓圓圈圈圓圓~深度學習:循環神經網路 RNN、跟你我一樣選擇性記憶的神經網路?深度學習:長短期記憶 LSTM,以及每天成為更好的自己!神經網路也是!深度學習模型 GRU 等三篇文章中有提到,因為這兩種神經網路模型都是由前到後地對資料進行「學習」,且相對於簡單的機器學習模型,神經網路有記憶特性,因此可以考慮到上下文的關係(儘管不同種神經網路有其各自的缺陷)。然而,LSTM 同樣也繼承著循環神經網路的其中一個缺點,而 GRU 雖然運算速度比較快,但作為 RNN 的一員,也是在劫難逃,而這個缺點就是無法考慮「下上文」的關係。
什麼意思?
下上文的關係
想像一下,我們要理解一段文字中的某一個字時,不只需要了解這個字的上一個字,有時候也會需要知道這個字的下一個字是什麼,才能確定這個字所真正代表的意義。舉例來說,讓我們看看以下這張圖:

source: Bi-LSTM
在圖中,單從前面的said並沒有辦法確定Teddy是什麼意思,因為Teddy有可能是一個人名(美國前總統 Teddy Roosevelt),也有可能是一種玩具(泰迪熊),而要確認Teddy指的是什麼,就會需要Teddy後面的字。比如說在這裡的狀況,若後面是bear,那就是一種玩具;若後面是大寫名詞,那代表這裡的Teddy很有可能是人名。
不然就是,左到右 LSTM 今天所學到的句子是「魯夫出海時搭著」,而右到左 LSTM 所學的是「打倒了近海王者」,那麼對於一個模型來說,有了上下文的資訊,就能比較準確地預測在中間的字是什麼吧!而對於RNN體系的單向神經網路來說,以上這些任務的表現就比較差了。
也就是說,我們前三天所介紹的三種模型:RNN、LSTM、GRU,都沒有辦法有效地解決這個問題。這時機器學習學家就想
「那既然原來的LSTM是從左邊到右邊學習,那就再放另一條LSTM從右邊到左邊,就好啦!」
當然我把它變得超級白話啦!但真的原理就是這麼簡單。所謂的BiLSTM,就是把從左到右的LSTM,以及從右到左的LSTM合在一起,就這樣!不可能是什麼雙性戀的LSTM的吧,誰知道LSTM的自我認同是什麼呢?(X)
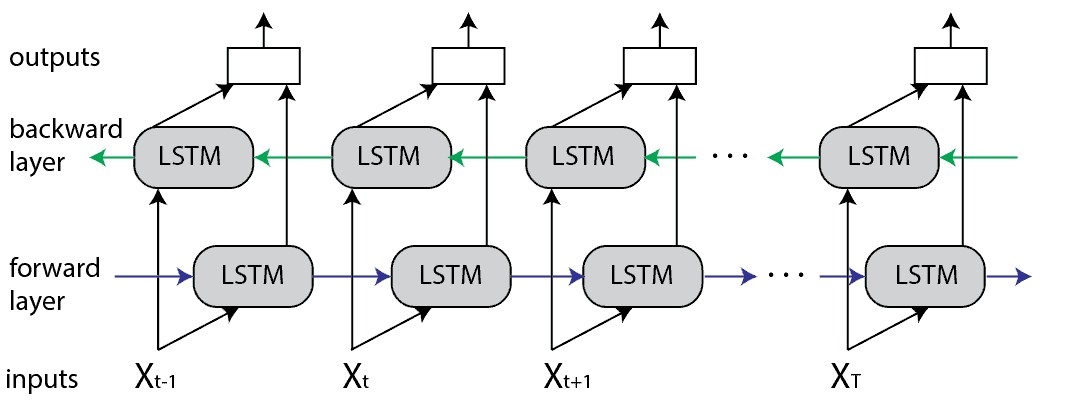
從圖中我們可以看到,每一個節點的輸出,都是左到右 LSTM 跟右到左 LSTM 所綜合的結果,這就是我們前面所說,單純將兩個方向的 LSTM 結合,其實就可以很有效地解決RNN體系無法理解「下上文」的缺陷。
問題與討論
所以 BiLSTM 通常也可以有效地解決各類的自然語言處理任務,像是文本分類、機器翻譯、實體辨識等等,除此之外,在聲音辨識中,BiLSTM也是可以佔有一席之地的喔!
不過熟悉我前面文章風格的都知道,接下來就要講不好的地方啦!俗話說:「有一好,沒兩好。」記得前面在講LSTM的時候,有提到因為在節點中加入了三個門閥(輸入閥、遺忘閥、輸出閥),所以不管是訓練時間還是運算資源,消耗量都相當可觀。那聰明的你可以想想看,兩條 LSTM 會怎麼樣呢?
沒錯,BiLSTM是個運算量更大、訓練時間更久的深度學習模型!你可能會想說,有LSTM就有BiLSTM,那有GRU,就會有BiGRU吧?是有BiGRU的,但通常大家都會直接轉向我們自然語言處理界的超大型巨人 BERT 了。也就是說,從明天開始,會花三篇的篇幅來,從注意機制(attention)開始,一路到transformer,接著到BERT的介紹,之後才會進入實作,還請大家一定要撐下去啊(其實是在對自己說)!
若大家沒事的話,也可以點進昨天的文章,不知道為什麼點閱率少得可憐啊!
➡️ 【NLP】Day 17: 每天成為更好的自己!神經網路也是!深度學習模型 GRU
➡️ 【NLP】Day 16: 跟你我一樣選擇性記憶的神經網路?深度學習:長短期記憶 LSTM
➡️ 【NLP】Day 15: 圓圓圈圈圓圓~深度學習:循環神經網路 RNN