【NLP】Day 7: 現出你的原形!tokenization、lemmatization、stemming
「隱藏著黑暗力量的鑰匙啊,在我面前顯示真正的力量! 跟你訂下約定的小櫻命令你,封印解除!」
《庫洛魔法使》木之本櫻
昨天我們學到了中文斷詞的方法,還有一些需要釐清的觀念,以及我個人的一些想法。中文學完了,那英文呢?英文的斷詞方法跟中文有什麼不同的地方嗎?我們今天就一起來瞧瞧世界通用的語言之一,英文,在自然語言處理中是怎麼進行的?
昨天我們提到了中文這個語言其中的一個特性是,所有字都是黏在一起的,而相對於英文來說,由於英文中間都會以空格分開,所以在這個問題上就不用像中文一樣考量比較多一點,其實這也告訴我們不同語言在自然語言處理上都會有不同的處理方式,沒有單一的最好處理方式,只有最適合的方法。
英文斷詞叫做tokenization,雖然說英文的斷詞並不像中文一樣全部都黏在一起,但是英文也有英文的難處。這是因爲英文的詞尾常常出現變化,比較兩種語言起來,中文卻可以說是完全沒有字尾變化。而英文這種詞尾變化在語言學裡面則稱呼為inflection,而如何處理inflection,就是英文的自然語言處理上一個常被討論的議題。
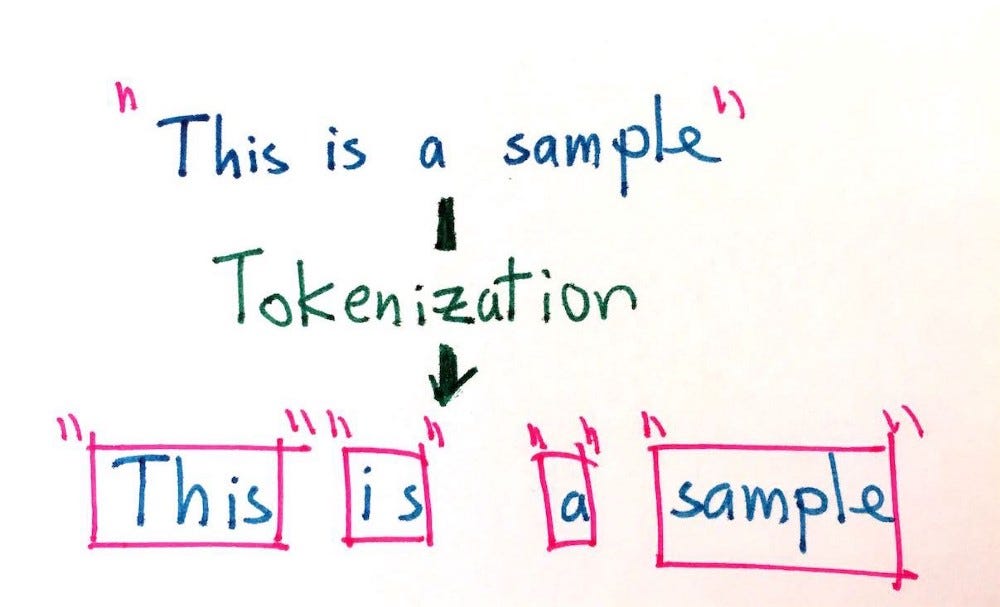
我們就先來看看tokenization的做法吧!以下這段是由海賊王的英文版維基百科中所擷取下來的一段文字。我們要用的是自然語言處理很常用的函式庫,叫做nltk(Natural Language Toolkit),裡面提供了特別多的函式幫助你可以更好地進行自然語言處理。
1 | |
1 | |
1 | |
照慣例,我們先來看看輸出結果有什麼令人不滿意的地方。其中我們可以發現,有很多應該是要連在一起的字,由於tokenizer的緣故都被分開了,那其實這樣的結果會影響我們之後的下游任務,一個比較常見且簡單的方法是在這些應該連在一起的字中間加上底線,這樣就會被分成同一個token了。程式碼的部分可以這麼寫:
1 | |
1 | |
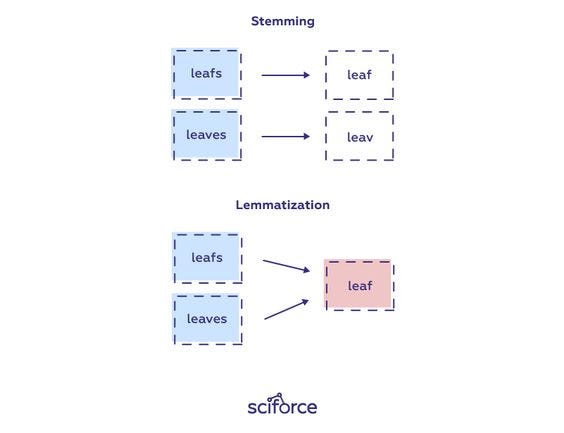
等我們都斷好詞之後,若有需求的話,有兩種將整個文本標準化的方法,像小櫻一樣,讓這些字現出原形,展現出其真正的力量:一種是stemming、另一種則是lemmatization。
Resource: https://tr.pinterest.com/pin/706854104005417976/
stemming
stemming在於找出每一個字的字根。你可能也會發現這些stemming過後的字有些跟你印象中的字根不太一樣,所以要注意,這裡的字根並不一定是字典上所記載的字根,再加上這些字是以rule-based的方法打造而成的,只是為了找出每個字的較短形式。
1 | |
1 | |
lemmatization
跟stemming不一樣的是,lemmatization不只是把字切斷,而是透過字彙庫的建置,提供詞幹的結果。簡單來說就是比較正確的stemming啦!
1 | |
1 | |
把他加入句子之後就會變成這樣:
1 | |
1 | |
好的,那今天就介紹到這裡囉,明天就要來介紹TF-IDF以及Bag of Words囉!我們明天再見吧!